











- Product Details
- Feedback (4347)
- Shipping& Payment






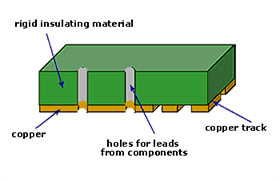
Single Side PCB
Single-Side PCB is the simplest and most common type of PCB. It was the first device used for the interconnection and assembly of electronic components forming a cohesive and functional operating system. The primary industry that uses these boards is the consumer electronics industry.
Double Side PCB
Double Side PCB have made circuit in 2 layer of different PCB side that both layer has connect by via PTH (Plated Through Hole) which depend on design this is more complex than Single Side PCB.
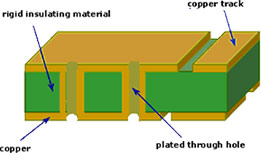
Multi Layer PCB
Multi Layer PCB have more layer than double side PCB, it has many circuit layer between Top side and Bottom side of PCB and also each layer can connect with via PTH (Plated Through Hole), this type is more complex than double side PCB.
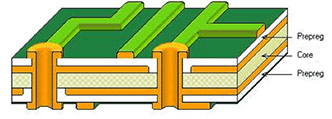
Gerber file (RS-274-X)
We offer a full range of printed circuit board capabilities to fit all of your PCB needs.Currently we accept 5 PCB file formats ( gerber file, .pcb, .pcbdoc .cam or .brd file format) for PCB fabrication. But if you design your boards with Sprint-Layout software, you can send the .lay6 file to service@pcbway.com for manually generating Gerber files.
- Gerber file format: RS-274-X
- Gerber file naming:
- GTL Gerber top layer
- GTO Gerber top overlay
- GTS Gerber top solder
- GBL Gerber bottom layer
- GBO Gerber bottom overlay
- GBS Gerber bottom solder
- GKO Gerber keepout layer
- DRD Excellon drill file
 1.6mm (Default)
1.6mm (Default)
PCB Board Thickness
0.4mm, 0.6mm, 0.8mm, 1.0mm, 1.2mm, 1.6mm, 2.0mm, 2.4mm
Please contact us if your board exceeds these.
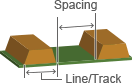
Min track/spacing
Min. Line Spacing & Min. Line Width: 4/4mil 5/5mil 6/6mil ↑
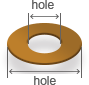
Min hole size
0.2mm 0.25mm 0.3mm ↑

Silkscreen
White, Black, None

Finished Copper
1oz/2oz/3oz(35μm/70μm/105μm)
Inner Layer Copper Thickness:1oz/1.5oz(35μm/50μm)
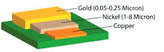
Surface Finishing
HASL with lead,HASL lead free,Immersion gold,Hard Gold ,OSP...
PCBWay Quality control
As the circuit boards are manufactured, and also after they are complete, we subject them to strict tests and checks:
- E-Test
- A.O.I. – Test (Automated Optical Inspection)
- X-ray (check registration accuracy for multilayers)
- CCD – Camera Controlled Drilling
-
Impedance control

The testing of our SMD stencils includes:
Real-Time Process Control, monitors the cutting process for every aperture in real time
optical (sight) check
verification of manufacturing tolerances

-
Quality Silk Screen Printing
Adopts high quality ink and printing technology to ensure clear and readable legend


-
High Quality Substrates
Uses highest quality substrates to endure the harsh environments

-
Diversified Processing Technology
Offers gold plating and gold finger PCB prototyping service, offers red and blue solder mask for prototypes

Classify by Rigid or Flex
-
 Rigid PCB
Rigid PCB
-
 SMD Stencils
SMD Stencils
-
 Aluminum Board
Aluminum Board
-
 Flexible PCB
Flexible PCB
-
 Rigid + Flex PCB
Rigid + Flex PCB
-
 Metal core Board
Metal core Board
-
 Electronic component
Electronic component
- Smart Devices
- Commercial, industrial and automotive
- Medicine
- University, school and amateur
Quick Turn Time PCB Prototyping and Production Services
Need a few boards fast?
We specialize in Quick turn PCB services with an industry leading turnaround time as fast as 24 hours.
Need more control over features?
PCB Prototypes,Special Production,Flexible PCBs,Rigid-Flex PCBs,Metal core PCBs,High Frequency PCBs,
High-TG PCBs,Aluminum PCBs,SMD Stencils,Turn-Key PCB Assembly Services and so on.
Need an affordable option on small quantities?
Manufacturer Direct Pricing,Minimum quantities requirements
Choose ValueProto and get value pricing for 1-2 layer boards.
We Are Not A Broker
Professional PCB prototype with guaranteed quality for PCB prototype, We can produce high-quality PCBs with competitive price both for prototypes and low volumes.
Having been in the PCB prototype business for more than a decade, PCBWay.com is a proud supplier of prototyping PCBs and low-volume production. Our quick-turn prototype service can be as short as 24 hours without sacrificing the quality. Our small run production ensures you the best combination of quality and cost effectiveness, that is why we have our customers spreading over 80 countries in different industries. You will be experiencing hassle-free online purchase of your PCBs from our web-based quote to final delivery. With our professional service team, you can have questions and puzzles solved in the most responsive way. We test every piece of your PCB before DHL and other courier staff picks up your box, and you can track your order using our industry-leading software for its processing status such as fabrication, shipping etc., We know that loyal customers are our most valued assets, and we also know good quality and on-time delivery creates loyal customers. We not only are sending quality PCBs, but also delivering total satisfaction to you!

Packaging Details











